
کدپیج یا مجموعهکد (Code Page) سامانهایست مشابه مجموعهنویسه که به هر نویسه، دنباله مشخصی از بایتها را متناظر میکند (بر خلاف مجموعهنویسه که به هر نویسه تنها یک عدد اختصاص میدهد).
هر زبان یا بومی ممکن است کدپیجهای متفاوتی استفاده کند؛ برای نمونه کدپیج ویندوز-۱۲۵۲ برای زبان انگلیسی و بیشتر زبانهای اروپایی استفاده میشود و کدپیج اُئیاِم ۹۵۲ برای کانجی ژاپنی به کار میرود. برای نمایش کدپیجها میتوان از یک جدول که مقادیر بایتهای تخصیصیافته به هر نویسه را مشخص میکند استفاده کرد. بسیاری از کدپیجها در بازه 0x00 – 0x7F نویسههای یکسانی با اَسکی دارند و به اصلاح با اَسکی سازگاری دارند.
Unicode
یونیکُد ((Unicode استانداردی صنعتی برای کدبندی نویسههای رایانهای و نمایش و پردازش متن به اکثر زبانهای دنیا است. هر زبان یک قالب یونیکد دارد.
هدف یونیکد رفع محدودیتهای موجود در کدبندی نویسههای قدیمی است، مانند کدبندیهایی که بر پایه استاندارد ISO 8859 تعریف شدهاند، که استفاده گستردهای در کشورهای مختلف پیدا کردهاند، ولی با یکدیگر سازگار نیستند. بسیاری از کدبندیهای قدیمی این مشکل مشترک را دارند که امکان پردازش متنهای دوزبانه (معمولا به وسیله نویسههای لاتین و نمادهای محلی) را فراهم میکنند، ولی پردازش بیش از دو زبان را ممکن نمیکنند.
نقش یونیکد در پردازش متن این است که به جای یک تصویر برای هر نویسه یک کد منحصر به فرد ارائه میکند. به عبارت دیگر، یونیکد یک نویسه را به صورت مجازی ارائه میکند و کار ساخت تصویر (شامل اندازه، شکل، قلم، یا سبک) نویسه را به عهده نرمافزار دیگری مانند مرورگر وب یا واژهپرداز میگذارد. موفقیت یونیکد در یکی کردن کدبندی نویسهها سبب استفاده گسترده اش در جهانیسازی و بومیسازی نرمافزارها شدهاست. این استاندارد در بسیاری از فناوریهای اخیر پیاده شدهاست از جمله: اکس ام ال، زبان برنامهنویسی جاوا، چارچوب دات نت مایکروسافت و سیستم عاملهای مدرن.
یونیکد میتواند توسط کدبندیهای مختلفی پیادهسازی شود. پرکاربردترین رمز نگاریها عبارت اند از: UTF-8، و UCS-2 (دیگر اعتبار ندارد) و UTF-16.
کدبندی UTF-8 برای کدبندیهای موجود در استاندارد اسکی تنها ۱ بایت استفاده میکند. کد نویسههای موجود در رمز نگاری اسکی، در هر دو کدبندی یکی است. این رمز نگاری حداکثر ۴ بایت برای هر نویسه استفاده میکند.UCS-2 برای تمام نویسهها از ۲ بایت استفاده میکند بنابراین نمیتواند تمام نویسههای موجود در استاندارد فعلی یونیکد را کدبندی کندUTF-16 . کدبندی UCS-2 را گسترش میدهد و برای نویسههای باقیمانده از ۴ بایت استفاده میکند.
EBCDIC
EBCDIC در سال های 1963 و 1964 توسط IBM طراحی شده است. این یک رمزگذاری کاراکتر هشت بیتی است که به طور جداگانه از طرح رمزگذاری 7 بیت ASCII توسعه می یابد.
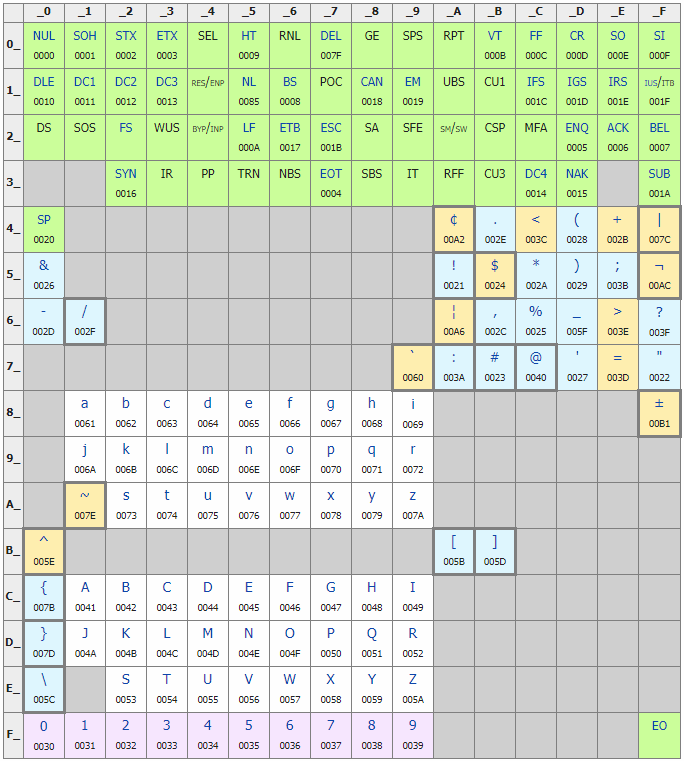
EBCDIC Table
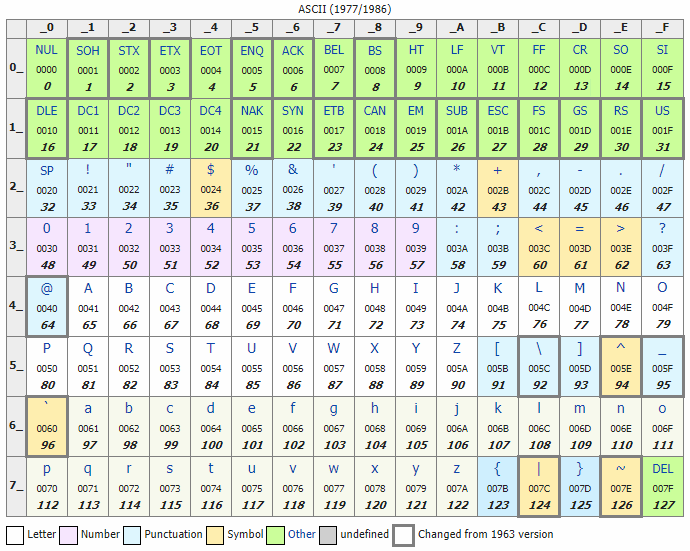
ASCII
«انجمن ملی استاندارد آمریکا» (America National Standard Association, ANSI) در ۶ اکتبر ۱۹۶۰ شروع به کار بر روی «اسکی» (ASCII) کرد. طرح اولیه این کدگذاری به صورت ۵ بیتی در کدهای تلگرافی داشت و توسط «امیلی بادوت» (Emile baudot) ابداع شد. اما در پایان کمیته طراح تصمیم به استفاده از کد ۷ بیتی گرفت.
۷ بیت امکان کدگذاری از ۱۲۸ کاراکتر را میدهد. با توجه به اینکه کاراکترهای انگلیسی فقط به ۱۲۸ عدد نیاز داشتند، استفاده از ۷ بیت به معنی به حداقل رساندن هزینه انتقال این دادههاست. (برعکس ۸ بیت(
۳۲ کاراکتر اول اسکی برای کاراکترهای کنترلی استفاده میشود. این کاراکترها برای انتقال دستورالعملهای خاصی به دستگاههای دیگر مثل پرینتر مورد استفاده قرار میگیرد. برای مثال کاربر میتواند یک خط را … کند، یک کاراکتر را حذف کند و در برخی دستگاهها مثل «تله تایپ مدل ۳۳» (TeleType model 33) زنگ را به صدا درآورد.
!”#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
نوع توسعه یافته این سیستم کد گذاری، ۸ رقمی بوده و قادر است ۲۵۶ کاراکتر را کدگذاری کند.
برای نمونه کد حرف “W” عدد ۸۷ میباشد، شما میتوانید در یک ویرایشگر متنی در حالی که دکمه Alt را فشار دادهاید عدد ۸۷ را وارد نمایید تا با رها کردن Alt حرف “W” را مشاهده نمایید.
از این سیستم در PCها استفاده میشود.
اصلاحات استاندارد ASCII:
- ASA X3.4-1963
- ASA X3.4-1965 (approved, but not published, nevertheless used by IBM 2260 & 2265 Display Stations and IBM 2848 Display Control
- USAS X3.4-1967
- USAS X3.4-1968
- ANSI X3.4-1977
- ANSI X3.4-1986
- ANSI X3.4-1986 (R1992)
- ANSI X3.4-1986 (R1997)
- ANSI INCITS 4-1986 (R2002
- ANSI INCITS 4-1986 (R2007
- ANSI INCITS 4-1986 (R2012)
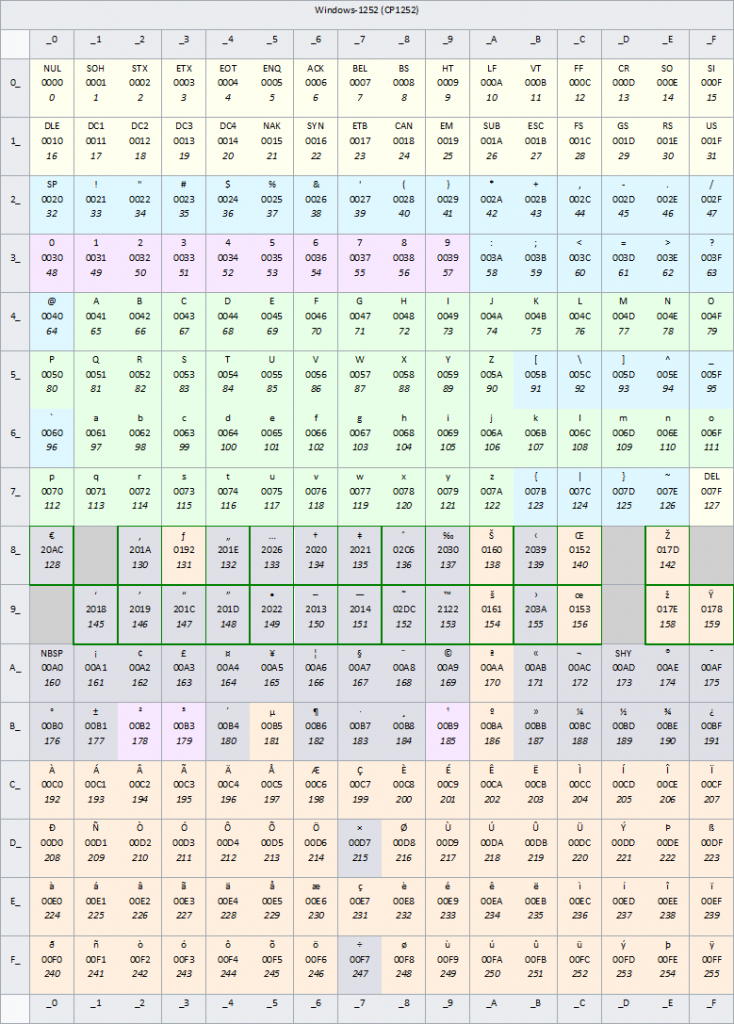
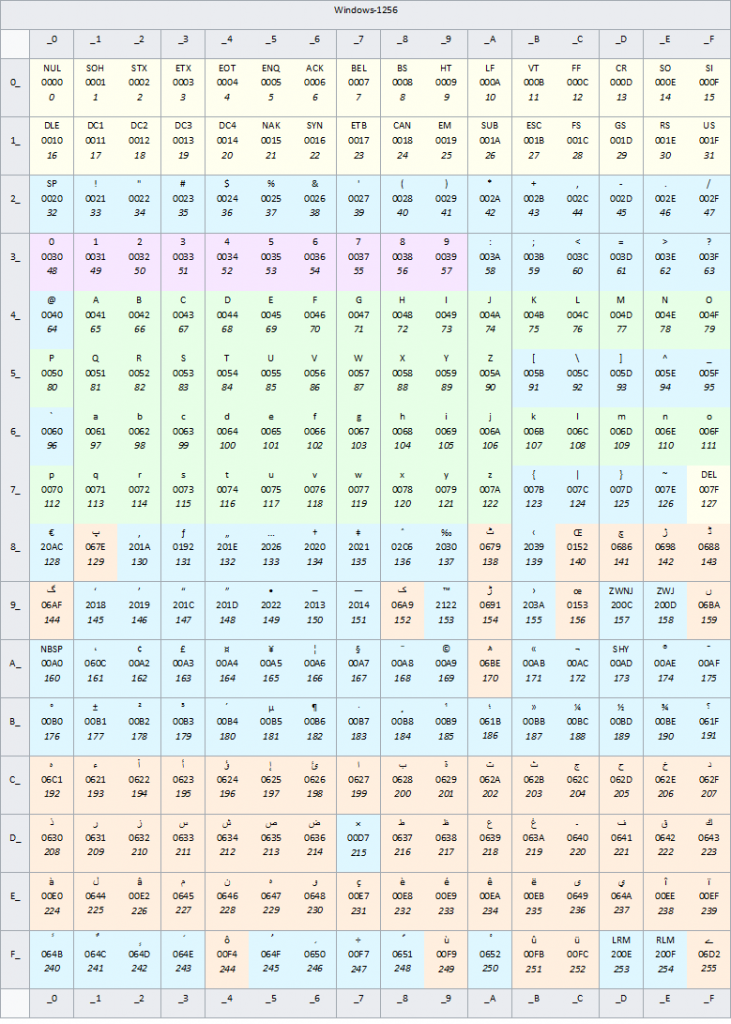
Win 1256
ویندوز-۱۲۵۲ یکی از کدپیجهای ثبتشده توسط شرکت مایکروسافت است. این کدپیچ بالامجموعهای از استاندارد لاتین۱ (ایزو/آیئیسی ۸۸۵۹-۱) است که از اکتتهای بازه 0x80 تا 0xF9 (که معمولاً برای نویسههای کنترلی به کار میروند) برای نمایش نویسههای افزوده خود مانند علامت نشان تجاری (™) استفاده میکند. به علت استفاده از همین کدپیج است که مرورگرهای غیرمایکروسافتی در بسترهای غیرمایکروسافتی گاهی برخی نویسههای را صحیح نمایش نمیدهند.
ویندوز-۱۲۵۲ نیز همانند یوتیاف-۸ با اَسکی سازگاری دارد. این یعنی ۱۲۷ نویسه نخست آن کاملاً مشابه اَسکی پیادهسازی میشوند.
مایکروسافت به برنامهنویسان توصیه کرده است که برای پشتیبانی بهتر از زبانها و ابهامزایی کمتر، به جای استفاده از این کدپیچ یا هر کدپیج دیگری، در نرمافزارهای کاربردی خود از یونیکد استفاده کنند .
برای مشاهده دقیقتر جدول میتوانید به این آدرس مراجعه نمایید.
WIN 1256
ویندوز-۱۲۵۶ نام یک کدپیج در مایکروسافت ویندوز برای نوشتن زبان عربی (و احتمالاً برخی زبانهای مشابه مانند فارسی و اردو) است.
این کدپیج به هر حرف از الفبای عربی (و نه گلیفهای متفاوتی که ممکن است از نوشتن یک حرف پدید آیند) یک کد اختصاص میدهد. با وجود اینکه حروف عربی موجود در بازه C0-FF این کدپیچ به ترتیب الفبای عربی هستند، اما در میانشان حرفهای لاتین نیز وجود دارد؛ این حروف لاتین کدبندیای مشابه کدپیچ ویندوز-۱۲۵۲ که برای زبان فرانسوی استفاده میشود دارند. علت آمدن این حروف در کدپیچ عربی، وجود قرابت تاریخی میان این دو است که اجازه نوشتن متون عربی-فرانسوی را با استفاده از این کدپیچ فراهم میکند (با این وجود این کدپیچ حروف بزرگ دارای دایهکریتیک را شامل نمیشود)
به کاربران توصیه میشود برای پشتیبانی بهتر از زبانها و ابهامات کمتر، به جای این کدپیچ یا هر کدپیج دیگری، از یونیکد استفاده کنند.
UTF-8
نوعی نویسه کدگذاری برای نوشتار است که فرمت ۸ بیت را رمزگذاری میکند و در مجموعه یونیکدهای اسکی طراحی شده و برای جلوگیری از مشکلات endianness در یوتیاف-16 و یوتیاف-32 ساخته شده است. بیش از نیمی از وب سایتها در سراسر جهان از این یونیکد کدگذاری میشوند. به طور پیش فرض این نویسه کدگذاری در سیستم عامل، زبانهای برنامهنویسی،رابط برنامهنویسی نرمافزار و نرمافزارهای کاربردی مورد استفاده قرار میگیرد. همچنین این نویسه از مهمترین یونیکدهای کدگذاری در فونتها و نوشتارهای فارسی در صفحات وب و … محسوب میشود.
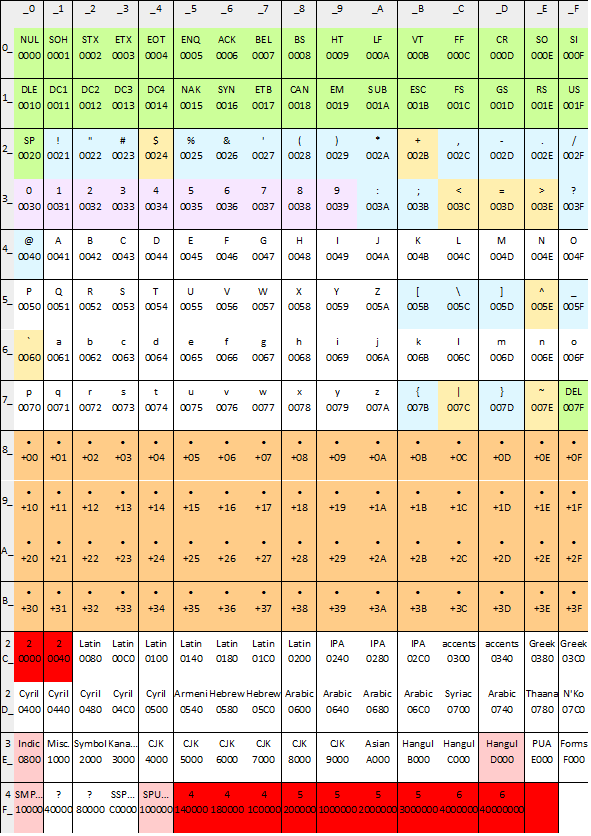
UTF-8
برای مشاهده دقیقتر جدول میتوانید به این آدرس مراجعه نمایید.
UTF-16
در اواخر دهه 1980، کار بر روی توسعه یک رمزگذاری یکپارچه برای مجموعه «مجموعه کاراکترهای جهانی» (UCS) آغاز شد که جایگزین زودهنگام زبان پیشین با یک سیستم هماهنگ شده بود. هدف این بود که تمام کاراکترهای مورد نیاز را از بیشتر زبان های جهان، و همچنین نمادهای از حوزه های فنی مانند علم، ریاضیات و موسیقی، شامل شود.
utf-16 یکی از پیادهسازیهای یونیکد است. در این پیادهسازی برای ذخیرهسازی کاراکتر از ۱۶ بیت یا ۳۲ بیت استفاده میشود.
در پیادهسازی utf-16 برای ذخیرهسازی این زیرمجموعه از کاراکترهای یونیکد از ۱۶ بیت استفاده میشود و برای بقیه کاراکترها از ۳۲ بیت.
این کاراکترهای پرکاربرد کاراکترهای بین U+0000 و U+D7FF و بین U+E000 و U+FFFF هستند که به صورت مستقیم ذخیره میشوند.
650001
طبق گفته سایت ماکروسافت این کد نشاندهنده UTF-8 است.
IranSystem
کدبندی ایرانسیستم نام یک کدبندی نویسه قدیمی ۸ بیتی برای زبان فارسی است که توسط شرکت ایرانسیستم معرفی شد. این کدبندی در ایران و در برنامههای مبتنی بر سیستمعامل داس کاربرد گستردهای یافت به طوری که پرکاربردترین قالب برای تبادل متن فارسی بود و در تمامی برنامههای فارسی پشتیبانی میشد و در سکوهای وب نیز مورد استفاده قرار میگرفت. اما بعدها با معرفی ویندوز-۱۲۵۶ و ایزیری ۶۲۱۹ رفتهرفته کنار گذاشته شد. امروزه برخی برنامهها و اسناد تحت ویندوز و داسی که از این کدبندی استفاده میکنند همچنان یافت میشود و قلمهایی که برای این کدبندی ساخته شدهاند نیز وجود دارند ولی بیشتر برنامهها از کدپیج ۱۲۵۶ ویندوز یا یونیکد استفاده میکنند.
این کدبندی دارای چندین نسخه محلیشده است و برای آن مبدلهایی جهت تبدیل به یونیکد نوشتهشده. در هنگام تبدیل کدبندی ایرانسیستم به یونیکید باید به مسئله نیاز/عدم نیاز به استفاده از فاصله مجازی و اتصال مجازی دقت داشت؛ برای نمونه واژه «خانهها» که در کدبندی ایرانسیستم (به علت استفاده از شکل پایانی حرف «ه») بدون نیاز به فاصله مجازی نوشته میشود
(0xA1 0x91 0xF7 0xF9 0xFA 0x91) در یونیکد باید به 0x062E 0x0627 0x0646 0x0647 0x200C 0x0647 0x0627 تبدیل شود.
این قالب محدودیتها و مشکلات بسیاری دارد از جمله:
- ذخیرهسازی دیداری (بر اساس ترتیب نمایش چپ به راست) بهجای ذخیرهسازی مفهومی (بر اساس ترتیب خواندن)
- چندنمادی بودن (اختصاص دو، سه، یا چهار کد به اشکال مختلف حروف فارسی) به جای تکنمادی بودن (اختصاص فقط یک کد به هر حرف فارسی)
- کمبود برخی نویسهها (نمادهای متداولی چون همزه روی حروف، گیومه و نقطهویرگول)
- نداشتن کد گریز مورد تأیید ایزو برای ترکیب متنهایی غیر از فارسی و انگلیسی
- گسترشناپذیری
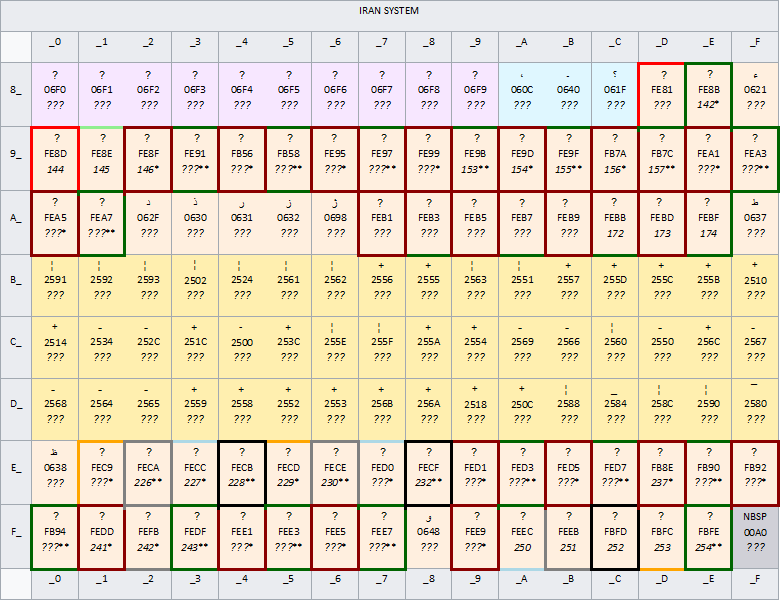
کدپوینت دادهشده متعلق به شکل جدا است، شکل پایانی این حرف دارای کدپوینتی جداگانه است.
**کدپوینت دادهشده برای شکل آغازین حرف است، شکل میانی این حرف دارای کدپوینتی جداگانه است.
برای مشاهده دقیقتر جدول میتوانید به این آدرس مراجعه نمایید.

{kind=link}